Cluster Stats In R - Static and Interactive Heatmap in R - Unsupervised Machine ... : Returns a list of class clustering_stats containing the statistics.
Cluster Stats In R - Static and Interactive Heatmap in R - Unsupervised Machine ... : Returns a list of class clustering_stats containing the statistics.. Clustering stability validation, which is a special version of internal validation. The one used by option ward.d (equivalent to the only ward option ward in r versions <= 3.0.3) does not implement ward's (1963) clustering criterion, whereas option ward.d2 implements that criterion. Clustering is a form of unsupervised learning because we're simply attempting to find structure within a dataset rather than predicting the value of some response variable. I've tried some functions such as. Asked feb 27, 2020 in r language by rahuljain1.
The api returns basic index metrics (shard numbers, store size, memory usage) and information about the current nodes that form the cluster (number, roles, os, jvm versions, memory usage, cpu and installed plugins). I imagine analyses might still run but that the analysis might not yield anything useful. However, cluster analysis typically needs quite a bit of data (more than 8 rows, as in your example) to identify clusters. Clustering is often used in marketing when companies have access to information like Computing cluster validation statistics in r.
r - How to create clustering plots which long and wide ... from i.stack.imgur.com I used the cluster.stats function that is part of the fpc package to compare the similarity of two custer solutions using a variety of validation criteria, as you can see in the code. Clustering stability measures will be described in a future chapter. Get_clustering_stats calculates statistics of a clustering. Hello every body, i am doing some clustering method that generates overlapping clusters and i want to calculate some clustering validation measures of my results and the results of other existing algorithms. The clustering optimization problem is solved with the function kmeans in r. Clustering is a broad set of techniques for finding subgroups of observations within a data set. Computing cluster validation statistics in r. Clustering is an unsupervised learning technique.
However, cluster analysis typically needs quite a bit of data (more than 8 rows, as in your example) to identify clusters.
Clustering is a broad set of techniques for finding subgroups of observations within a data set. The function cluster.stats() in the fpc package provides a mechanism for comparing the similarity of two cluster solutions using a variety of validation criteria (hubert's gamma coefficient, the dunn index and the corrected rand index). The clustering optimization problem is solved with the function kmeans in r. Convenient to look at it as a table # this code below will produce a dataframe with observations in columns and variables in row # not quite tidy data, which will require a tweak for plotting, but i prefer this view as an output here as i find it more comprehensive. Also that cqcluster.stats is a more sophisticated version of cluster.stats with more options. This particular clustering method defines the cluster distance between two clusters to be the maximum distance between their individual moreover, as added bonus, the rpuhclust function creates identical cluster analysis output just like the original hclust function in r. It is the task of grouping together a set of objects in a way that objects in the same cluster are more similar to each other than to objects in other clusters. However, i have two questions: The one used by option ward.d (equivalent to the only ward option ward in r versions <= 3.0.3) does not implement ward's (1963) clustering criterion, whereas option ward.d2 implements that criterion. Clustering is often used in marketing when companies have access to information like Clustering is an unsupervised learning technique. It is define in fpc package which provide a method for comparing the similarity of two clusters solution using different validation criteria. The cluster stats api allows to retrieve statistics from a cluster wide perspective.
However, cluster analysis typically needs quite a bit of data (more than 8 rows, as in your example) to identify clusters. It evaluates the consistency of a clustering result by comparing it with the clusters obtained after each column is removed, one at a time. In k.means.fit are contained all the elements of the cluster output In this post, i focus on the latter as it is a more exploratory type, and it can be approached differently: The clustering optimization problem is solved with the function kmeans in r.
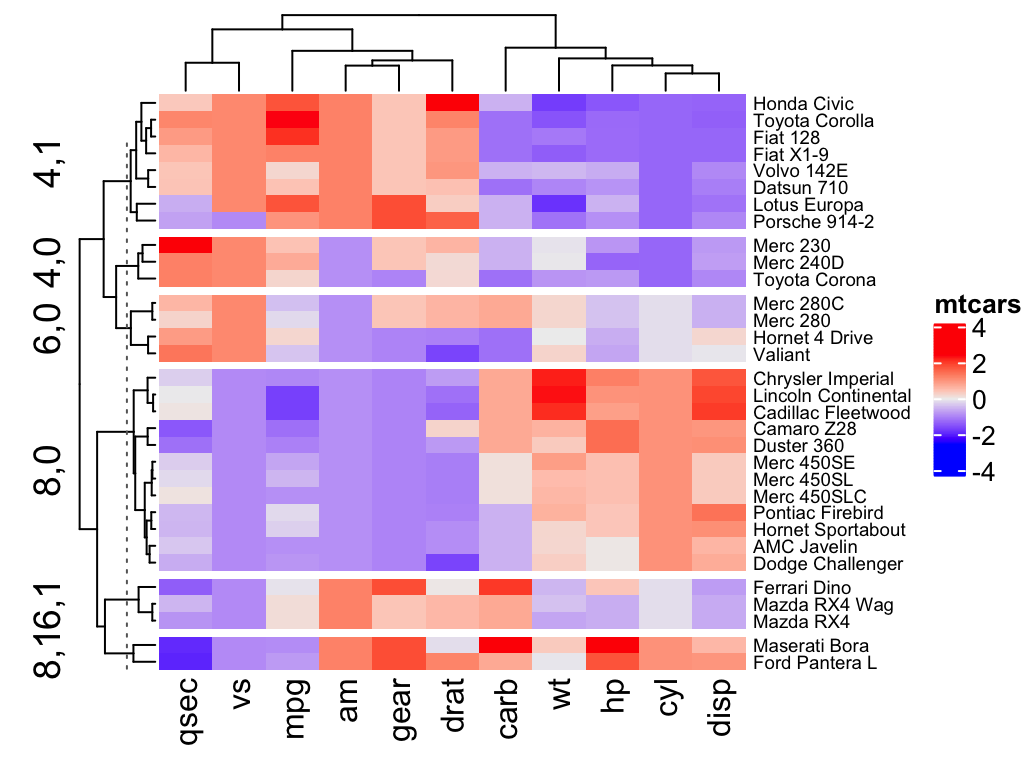
Heatmap in R: Static and Interactive Visualization - Datanovia from www.datanovia.com In k.means.fit are contained all the elements of the cluster output The function cluster.stats() in the fpc package provides a mechanism for comparing the similarity of two cluster solutions using a variety of validation criteria (hubert's gamma coefficient, the dunn index and the corrected rand index). Clustering analysis is performed and the results are interpreted. Clustering is a broad set of techniques for finding subgroups of observations within a data set. Or maybe i understand this wrong. External measures for clustering validation. Clustering stability measures will be described in a future chapter. Two different algorithms are found in the literature for ward clustering.
Clusters are merged until only one large cluster remains which contains all the observations.
However, cluster analysis typically needs quite a bit of data (more than 8 rows, as in your example) to identify clusters. The function cluster.stats() in the fpc package provides a mechanism for comparing the similarity of two cluster solutions using a variety of validation criteria (hubert's gamma coefficient, the dunn index and the corrected rand index). Clustering analysis is performed and the results are interpreted. Hello every body, i am doing some clustering method that generates overlapping clusters and i want to calculate some clustering validation measures of my results and the results of other existing algorithms. I've tried some functions such as. .to compare cluster.stats to pandas' df.describe in that we're taking some slice of the data (some specific cluster, or some specific columns of a dataframe) you may consider distcritmulti in those cases. Asked feb 27, 2020 in r language by rahuljain1. Clustering is a broad set of techniques for finding subgroups of observations within a data set. Two different algorithms are found in the literature for ward clustering. > define cluster.stats() in r language? Clustering is often used in marketing when companies have access to information like Dunn index is another measure of internal variation. It is define in fpc package which provide a method for comparing the similarity of two clusters solution using different validation criteria.
Asked feb 27, 2020 in r language by rahuljain1. Also that cqcluster.stats is a more sophisticated version of cluster.stats with more options. Clustering is a broad set of techniques for finding subgroups of observations within a data set. .to compare cluster.stats to pandas' df.describe in that we're taking some slice of the data (some specific cluster, or some specific columns of a dataframe) you may consider distcritmulti in those cases. Similarity is an amount that reflects the strength of relationship between two data objects.
Innovation Clusters: Collaboration for Early Childhood from 46y5eh11fhgw3ve3ytpwxt9r-wpengine.netdna-ssl.com > define cluster.stats() in r language? I've tried some functions such as. Clustering stability validation, which is a special version of internal validation. 1 ° is it possible to know which is the most viable cluster, 2 clusters or 5 clusters? However, i have two questions: It evaluates the consistency of a clustering result by comparing it with the clusters obtained after each column is removed, one at a time. The function cluster.stats() fpc package and the function nbclust() in nbclust package can be used to compute dunn index and many other cluster validation statistics or indices. Clustering is an unsupervised learning technique.
However, cluster analysis typically needs quite a bit of data (more than 8 rows, as in your example) to identify clusters.
1 ° is it possible to know which is the most viable cluster, 2 clusters or 5 clusters? However, cluster analysis typically needs quite a bit of data (more than 8 rows, as in your example) to identify clusters. Convenient to look at it as a table # this code below will produce a dataframe with observations in columns and variables in row # not quite tidy data, which will require a tweak for plotting, but i prefer this view as an output here as i find it more comprehensive. Clustering is an unsupervised learning technique. The function cluster.stats() in the fpc package provides a mechanism for comparing the similarity of two cluster solutions using a variety of validation criteria (hubert's gamma coefficient, the dunn index and the corrected rand index). Also that cqcluster.stats is a more sophisticated version of cluster.stats with more options. The function cluster.stats() in the fpc package provides a mechanism for comparing the similarity of two cluster solutions using a variety of validation criteria (hubert's gamma coefficient, the dunn index and the corrected rand index). > define cluster.stats() in r language? In k.means.fit are contained all the elements of the cluster output I used the cluster.stats function that is part of the fpc package to compare the similarity of two custer solutions using a variety of validation criteria, as you can see in the code. Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster) are more similar (in some sense) to each other than to those in other groups (clusters). It is the task of grouping together a set of objects in a way that objects in the same cluster are more similar to each other than to objects in other clusters. Clustering stability measures will be described in a future chapter.
You have just read the article entitled Cluster Stats In R - Static and Interactive Heatmap in R - Unsupervised Machine ... : Returns a list of class clustering_stats containing the statistics.. You can also bookmark this page with the URL : https://javierosane.blogspot.com/2021/05/cluster-stats-in-r-static-and.html
Share Awesome
Belum ada Komentar untuk "Cluster Stats In R - Static and Interactive Heatmap in R - Unsupervised Machine ... : Returns a list of class clustering_stats containing the statistics."


Belum ada Komentar untuk "Cluster Stats In R - Static and Interactive Heatmap in R - Unsupervised Machine ... : Returns a list of class clustering_stats containing the statistics."
Posting Komentar